What is DreamActor-M1?
DreamActor-M1 is a tool that creates realistic human animations. It uses a special method to control animations smoothly and adapt them to different sizes, from close-up portraits to full-body movements. By using a reference image, it can mimic actions from videos, ensuring the animations look consistent and true to the original person.
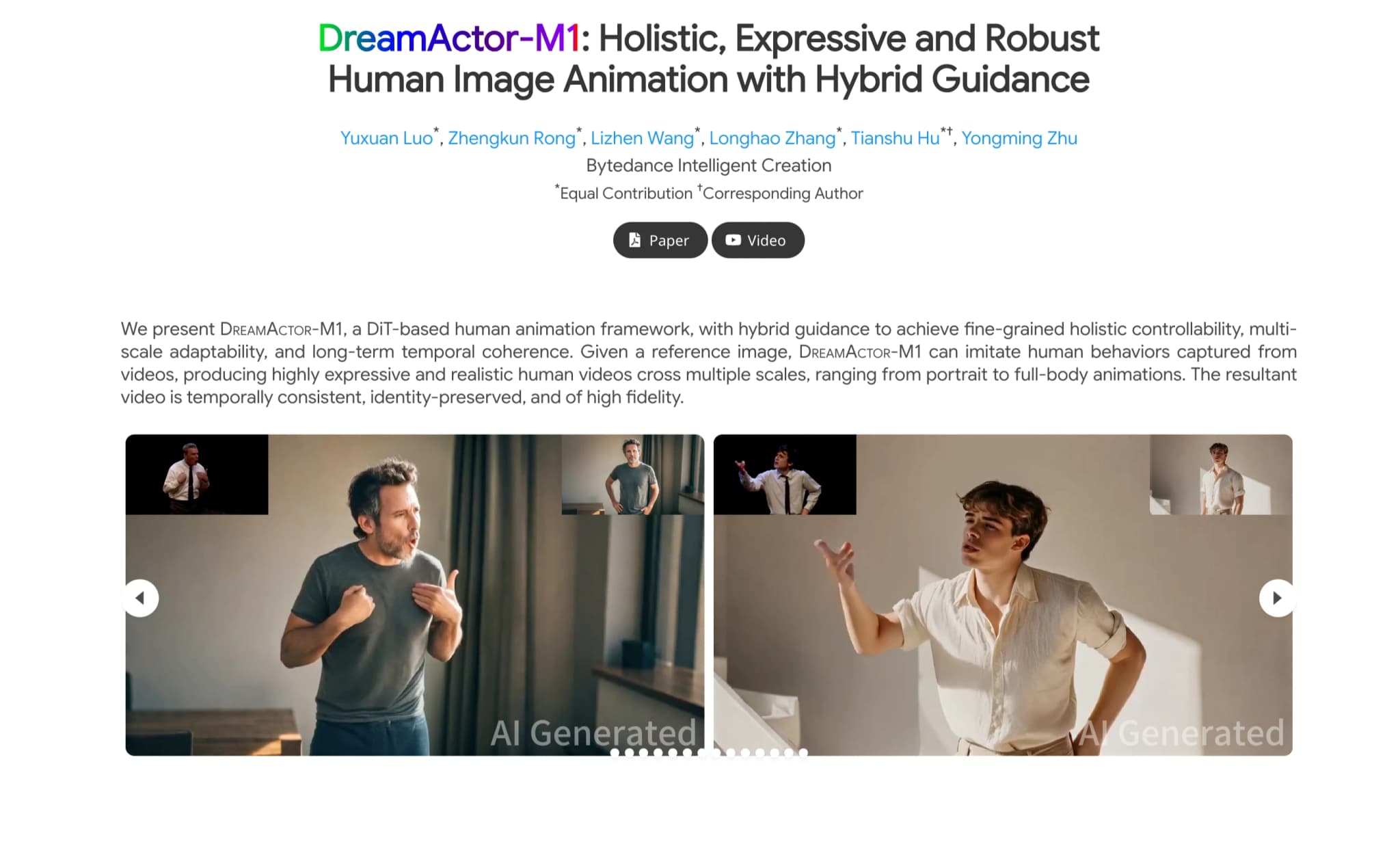
Overview of DreamActor-M1
| Feature | Description |
|---|---|
| AI Tool | DreamActor-M1 AI |
| Category | Human Animation Framework |
| Function | Realistic Human Animation |
| Generation Speed | Real-time Processing |
| Research Paper | arxiv.org/pdf/2504.01724 |
| Official Website | grisoon.github.io/DreamActor-M1/ |
Method Overview: Overview of DreamActor-M1
During the training stage, we first extract body skeletons and head spheres from driving frames and then encode them to the pose latent using the pose encoder. The resultant pose latent is combined with the noised video latent along the channel dimension. The video latent is obtained by encoding a clip from the input full video using 3D VAE. Facial expression is additionally encoded by the face motion encoder, to generate implicit facial representations.
Note that the reference image can be one or multiple frames sampled from the input video to provide additional appearance details during training and the reference token branch shares weights of our DiT model with the noise token branch. Finally, the denoised video latent is supervised by the encoded video latent.
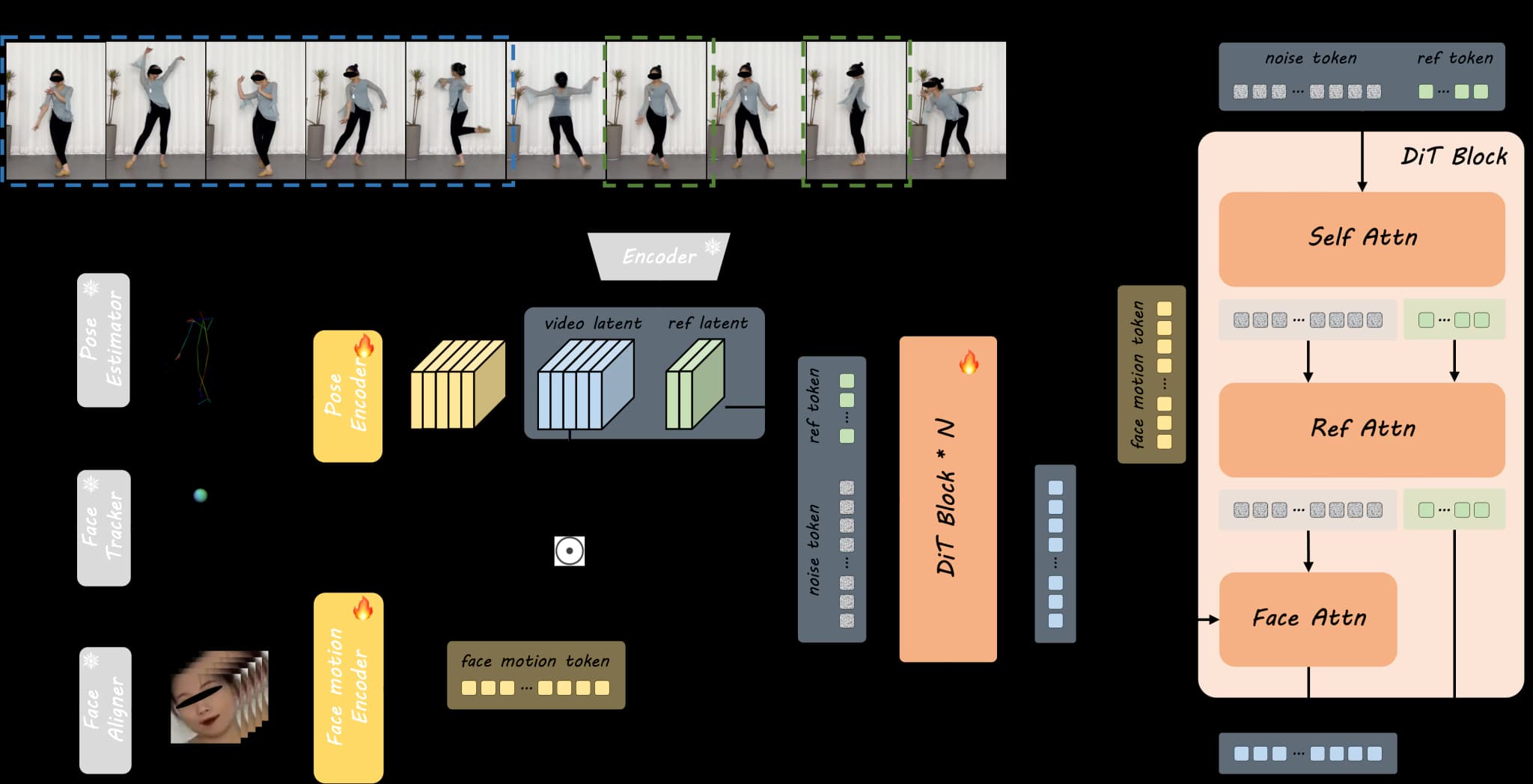
Within each DiT block, the face motion token is integrated into the noise token branch via cross-attention (Face Attn), while appearance information of ref token is injected to noise token through concatenated self-attention (Self Attn) and subsequent cross-attention (Ref Attn).
Key Features of DreamActor-M1
Diversity
Our method is robust to various character and motion styles.
Controllability and Robustness
Our method can extend to audio-driven facial animation, delivering lip-sync results in multiple languages. Our complementary visual guidance ensures better temporal consistency, particularly for human poses not observed in the reference. Our method supports transferring only a part of the motion, such as facial expressions and head movements.
Motion Guidance
Use a sophisticated control system that integrates implicit facial cues, 3D head models, and 3D body frameworks to deliver dynamic and expressive facial and body animations.
Scale Adaptability
Employs a step-by-step training approach that leverages multi-resolution datasets to effectively handle a range of body poses and image scales, from close-up portraits to full-body shots.
Appearance Guidance
Leverages motion sequences and visual references to ensure consistent temporal flow, especially in areas not previously encountered during intricate movements.
Examples of DreamActor-M1 in Action
Various character and motion styles.
How does DreamActor-M1 compare to state-of-the-art (SOTA) methods?
- Fine-grained motion control (expressive facial and body movements).
- Identity preservation (maintaining the subject's appearance).
- Temporal consistency (smooth transitions over long sequences).
- Robustness (handling unseen poses and complex motions).
Pros and Cons
Pros
- Fine-grained controllability for expressive animations
- Multi-scale adaptability from portrait to full-body
- Long-term temporal coherence in animations
- Supports selective motion transfer
- Audio-driven lip-sync animations in multiple languages
- Pros
Cons
- Requires high-quality reference images for best results
- Computationally intensive for high-resolution outputs
- Cons