What is DreamActor-M1?
DreamActor-M1 is een tool die realistische menselijke animaties creëert. Het gebruikt een speciale methode om animaties soepel te besturen en aan te passen aan verschillende formaten, van close-up portretten tot bewegingen van het hele lichaam. Door een referentieafbeelding te gebruiken, kan het acties uit video's nabootsen, waardoor de animaties consistent blijven en trouw aan de originele persoon.
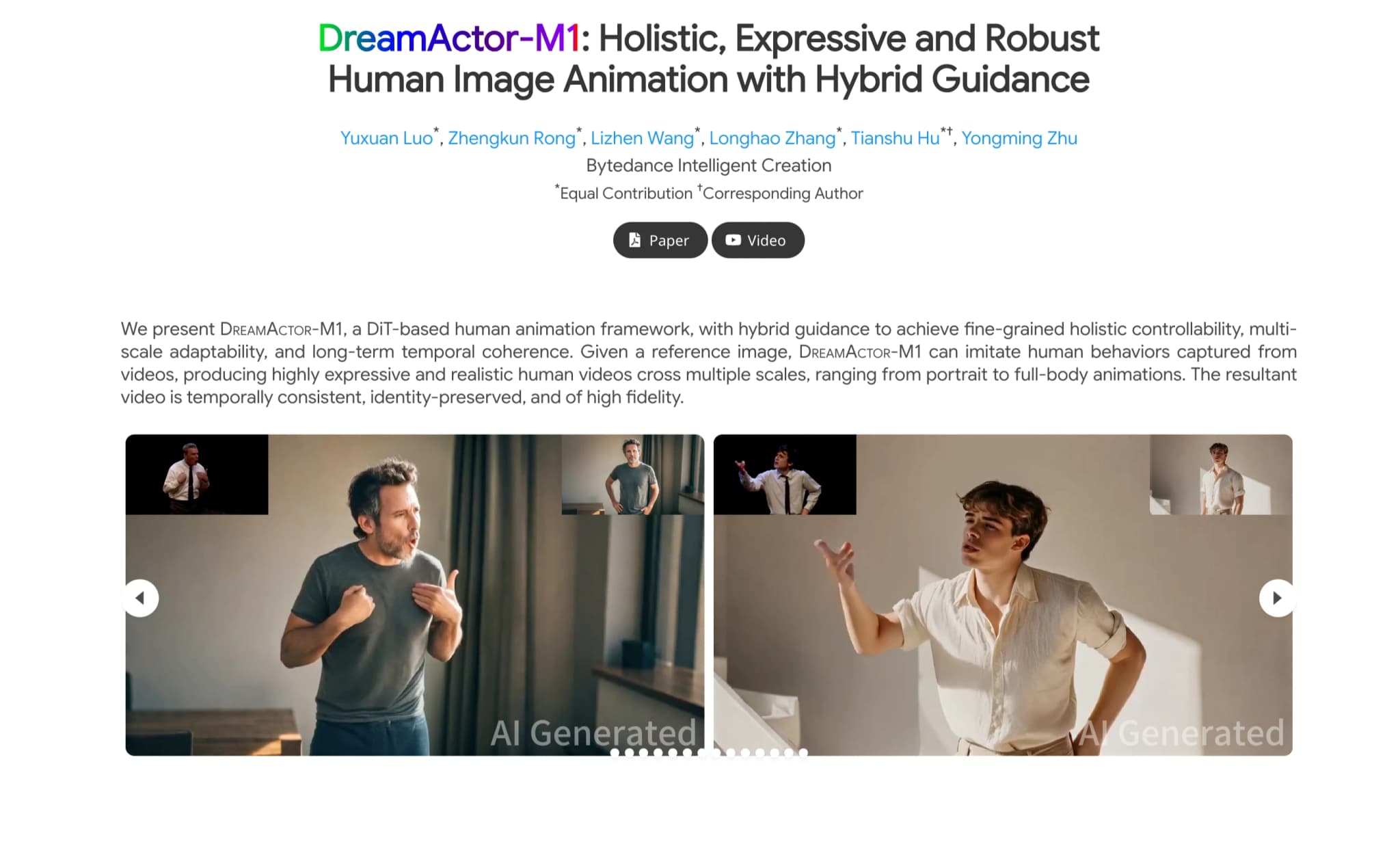
Overzicht van DreamActor-M1
| Functie | Beschrijving |
|---|---|
| AI Tool | DreamActor-M1 AI |
| Categorie | Human Animation Framework |
| Functie | Realistische Menselijke Animatie |
| Generatiesnelheid | Real-time Verwerking |
| Onderzoekspaper | arxiv.org/pdf/2504.01724 |
| Officiële Website | grisoon.github.io/DreamActor-M1/ |
Methode Overzicht: Overzicht van DreamActor-M1
Tijdens de trainingsfase extraheren we eerst lichaamsskeletten en hoofdbollen uit aandrijvende frames en coderen deze naar de pose-latent met behulp van de pose-encoder. De resulterende pose-latent wordt gecombineerd met de ruisende video-latent langs de kanaaldimensie. De video-latent wordt verkregen door een clip uit de volledige invoervideo te coderen met behulp van 3D VAE. Gezichtsuitdrukking wordt aanvullend gecodeerd door de gezichtsbeweging-encoder om impliciete gezichtsrepresentaties te genereren.
Merk op dat de referentieafbeelding een of meerdere frames kan zijn die uit de invoervideo zijn gesampled om extra verschijningsdetails te bieden tijdens training, en de referentietoken-tak deelt gewichten van ons DiT-model met de ruistoken-tak. Ten slotte wordt de ontruisde video-latent gesuperviseerd door de gecodeerde video-latent.
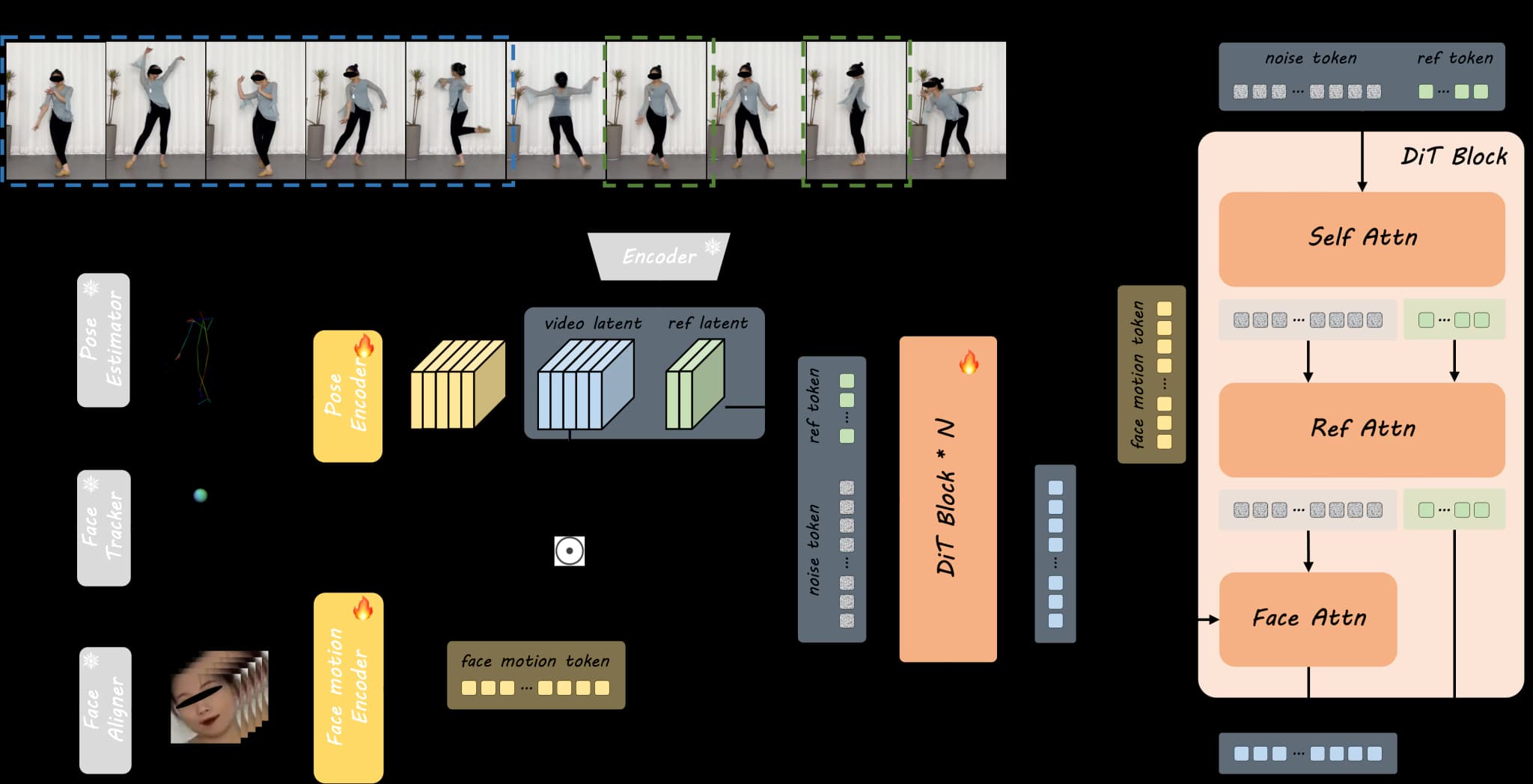
Binnen elk DiT-blok wordt de gezichtsbeweging-token geïntegreerd in de ruistoken-tak via cross-attention (Face Attn), terwijl verschijningsinformatie van ref-token naar ruistoken wordt geïnjecteerd via aaneengeschakelde self-attention (Self Attn) en daaropvolgende cross-attention (Ref Attn).
Belangrijkste Kenmerken van DreamActor-M1
Diversiteit
Onze methode is robuust voor verschillende karakter- en bewegingsstijlen.
Bestuurbaarheid en Robuustheid
Onze methode kan worden uitgebreid naar audio-gestuurde gezichtsanimatie, met lip-sync resultaten in meerdere talen. Onze complementaire visuele begeleiding zorgt voor betere temporele consistentie, vooral voor menselijke poses die niet in de referentie zijn waargenomen. Onze methode ondersteunt het overbrengen van slechts een deel van de beweging, zoals gezichtsuitdrukkingen en hoofdbewegingen.
Bewegingsbegeleiding
Gebruikt een geavanceerd controlesysteem dat impliciete gezichtskenmerken, 3D-hoofdmodellen en 3D-lichaamsraamwerken integreert om dynamische en expressieve gezichts- en lichaamsanimaties te leveren.
Schaalaanpasbaarheid
Gebruikt een stapsgewijze trainingsaanpak die gebruik maakt van multi-resolutie datasets om effectief een reeks lichaamshoudingen en beeldschalen te verwerken, van close-up portretten tot volledige lichaamsfoto's.
Verschijningsbegeleiding
Maakt gebruik van bewegingssequenties en visuele referenties om consistente temporele stroom te garanderen, vooral in gebieden die niet eerder zijn tegengekomen tijdens ingewikkelde bewegingen.
Voorbeelden van DreamActor-M1 in Actie
Verschillende karakter- en bewegingsstijlen.
Hoe vergelijkt DreamActor-M1 zich met state-of-the-art (SOTA) methoden?
- Fijnmazige bewegingscontrole (expressieve gezichts- en lichaamsbewegingen).
- Identiteitsbehoud (behoud van het uiterlijk van het subject).
- Temporele consistentie (vloeiende overgangen over lange sequenties).
- Robuustheid (omgaan met ongeziene poses en complexe bewegingen).
Voor- en Nadelen
Voordelen
- Fijnmazige bestuurbaarheid voor expressieve animaties
- Multi-schaal aanpasbaarheid van portret tot volledig lichaam
- Langdurige temporele coherentie in animaties
- Ondersteunt selectieve bewegingsoverdracht
- Audio-gestuurde lip-sync animaties in meerdere talen
- Voordelen
Nadelen
- Vereist hoogwaardige referentieafbeeldingen voor de beste resultaten
- Rekenintensief voor hoge-resolutie outputs
- Nadelen